Avid Amoeba
- 9 Posts
- 274 Comments
Joined 1 year ago
Cake day: July 5th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

 8·20 days ago
8·20 days agoNot noticeable with always-on Tailscale with the default split-tunnel mode. That is when Tailscale is only used to access Tailscale machines and everything else is routed via the default route.
The VPN should keep access to the homelab even when the external IP changes. Assuming the VPN connects from the homelab to the cloud. The reverse proxy would use the VPN local IPs to connect to services.
If you’re switching low power inconsequential things like LED lights, they’re OK.
This like most plugs in this format is not for inductive loads so it can only handle 300W with such:
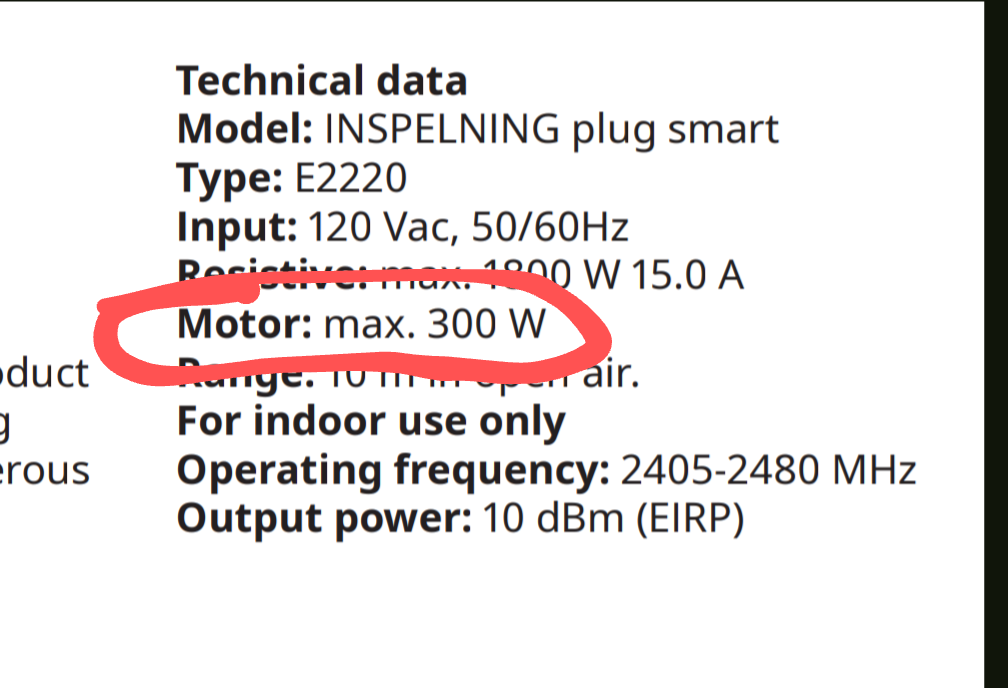
It might be OK if the AC units are small enough.
If you’re gonna be switching AC units, you likely want a plug that can switch inductive loads. Most can’t. Well they can but their relays crap out quickly. Here’s an example of a unit rated for inductive loads. It’s for NA and uses Z-wave so it’s not what you’re looking for. They explicitly call out it can be used for AC motors. Some units explicitly say they can’t be used for inductive loads but many don’t and you learn the hard way.
Thanks! I’ve been running 5x16T from SPD for over 6 months with zero issues.
And they package drives correctly.
I don’t know if SPD ships to where you are but a manufacturer recertified 16TB from them goes for ~$160. I have 7 drives from them so far, 5 in continuous use since spring, no issues so far.
It might also save it from shit controllers and cables which ECC can’t help with. (It has for me)
Unless you need RAID 5/6, which doesn’t work well on btrfs
Yes. Because they’re already using some sort of parity RAID so I assume they’d use RAID in ZFS/Btrfs and as you said, that’s not an option for Btrfs. So LVMRAID + Btrfs is the alternative. LVMRAID because it’s simpler to use than mdraid + LVM and the implementation is still mdraid under the covers.
And you probably know that sync writes will shred NAND while async writes are not that bad.
This doesn’t make sense. SSD controllers have been able to handle any write amplification under any load since SandForce 2.
Also most of the argument around speed doesn’t make sense other than DC-grade SSDs being expected to be faster in sustained random loads. But we know how fast consumer SSDs are. We know their sequential and random performance, including sustained performance - under constant load. There are plenty benchmarks out there for most popular models. They’ll be as fast as those benchmarks on average. If that’s enough for the person’s use case, it’s enough. And they’ll handle as many TB of writes as advertised and the amount of writes can be monitored through SMART.
And why would ZFS be any different than any other similar FS/storage system in regards to random writes? I’m not aware of ZFS generating more IO than needed. If that were the case, it would manifest in lower performance compared to other similar systems. When in fact ZFS is often faster. I think SSD performance characteristics are independent from ZFS.
Also OP is talking about HDDs, so not even sure where the ZFS on SSDs discussion is coming from.
Not sure where you’re getting that. Been running ZFS for 5 years now on bottom of the barrel consumer drives - shucked drives and old drives. I have used 7 shucked drives total. One has died during a physical move. The remaining 6 are still in use in my primary server. Oh and the speed is superb. The current RAIDz2 composed of the shucked 6 and 2 IronWolfs does 1.3GB/s sequential reads and write IOPS at 4K in the thousands. Oh and this is all happening on USB in 2x 4-bay USB DAS enclosures.
That doesn’t sound right. Also random writes don’t kill SSDs. Total writes do and you can see how much has been written to an SSD in its SMART values. I’ve used SSDs for swap memory for years without any breaking. Heavily used swap for running VMs and software builds. Their total bytes written counters were increasing steadily but haven’t reached the limit and haven’t died despite the sustained random writes load. One was an Intel MacBook onboard SSD. Another was a random Toshiba OEM NVMe. Another was a Samsung OEM NVMe.
Yes we run ZFS. I wouldn’t use anything else. It’s truly incredible. The only comparable choice is LVMRAID + Btrfs and it still isn’t really comparable in ease of use.
I use Immich. It does what you described as well.
I’m not sure why every time I look at this project, it rubs me the wrong way. Anyone found anything wrong with it?
As far as I can tell it dates back to at least 2010 - https://docs.oracle.com/cd/E19253-01/819-5461/githb/index.html. See the Solaris version. You can try it with small test files in place of disks and see if it works. I haven’t done it expansion yet but that’s my plan for growing beyond the 48T of my current pool. I use ZFS on Linux btw. Works perfectly fine.
I think data checksums allow ZFS to tell which disk has the correct data when there’s a mismatch in a mirror, eliminating the need for 3-way mirror to deal with bit flips and such. A traditional mirror like mdraid would need 3 disks to do this.
I see. Makes sense.